Nature of Set Selection in CAT 2025
Post-Examination: Navigating Perceived Difficulty and the Non-Negotiable Need for Temperament
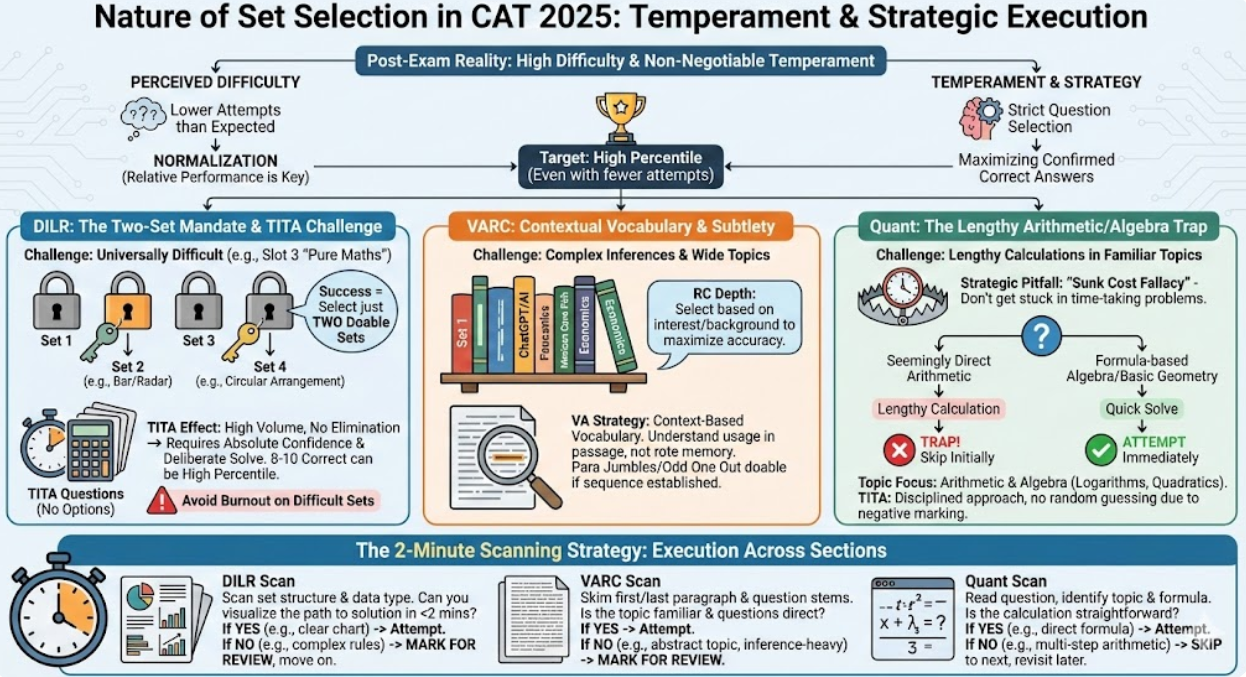
The collective feedback from all three CAT slots presents a unified picture: the examination relies heavily on a candidate's temperament and ability to adhere to a strict question selection strategy, often forcing attempts well below traditional expectations. The high level of difficulty, especially in DILR, confirms that performance will be judged relative to others (normalization).
The DILR Challenge and the "Two-Set" Mandate
DILR's difficulty was universally acknowledged, with Slot 3 posing significant difficulty, described as "pure maths" in one case (Import/Export set).
• The Power of Selection: Success was defined by the selection of just two out of the five sets. Students who failed to correctly identify the "doable" sets (such as the Bar/Radar chart in Slot 1, Ball & Holes/Authors in Slot 2, or the 10 People/Circular Arrangement in Slot 3) often "burnt out" time on difficult problems.
• The TITA Effect: The high volume of TITA questions (e.g., 11 TITA in Slot 1 DILR) requires absolute confidence in the solution, as there is no scope for option elimination. This necessitates a slower, more deliberate solve, even if the set is perceived as doable. The strategy shifts from maximizing attempts to maximizing confirmed correct answers, as even 8-10 DILR questions could suffice for a high percentile.
VARC: Contextual Vocabulary and Subtlety
VARC served as a critical differentiator. While the overall pattern of 4 RCs and 8 VAs remained, the complexity lay in contextual understanding and inference.
• RC Depth: RC topics required students to select passages based on interest to maximize accuracy. Specific topics (like ChatGPT/AI, Mexican Cave Fish, Complex Systems) spanned technology, biology, and economics, demanding a broad reading background.
• VA Strategy: VA questions, particularly Para Jumbles and Odd One Out, were deemed doable by some if the sequence and pairing could be established, even though the language was at times confusing. Crucially, vocabulary questions were context-based, requiring understanding of the word's usage within the passage rather than rote memorization.
Quant: The Lengthy Arithmetic/Algebra Trap
Quant section difficulty was driven by the length of the calculations, even for familiar topics.
• Topic Focus: Arithmetic (SI-CI, TSD, Profit/Loss, Ratio) and Algebra (including Logarithms, Quadratic Equations, and Maxima/Minima) dominated.
• Strategic Pitfalls: Students warned that starting with a seemingly direct Arithmetic question often led to a "time-taking" calculation, trapping them in the "sunk cost fallacy". The advice for future candidates is to rigidly apply the 2-minute scanning strategy to identify genuinely quick solves (like formula-based Algebra or basic Geometry, though some Geometry questions like Trapezium were also tricky) before committing to lengthy Arithmetic problems.
• TITA in Quant: Quant also had a significant TITA presence (6 to 8 questions). For challenging inequality problems or certain Algebra questions, a disciplined approach was needed, as random guessing on TITA questions is severely discouraged due to negative marking.
The Role of Normalization
Given the general consensus that Slot 3 was the most difficult, followed by Slot 1 (tougher than 2024), and Slot 2 (slightly more doable but still challenging), normalization will play a significant role. Students are advised not to feel demoralized by low attempt numbers, as a lower absolute score might yield a higher percentile if their specific slot was tougher. For instance, it was predicted that 4-5 correct DILR questions might be enough to clear the sectional 90th percentile cutoff.
The analysis repeatedly emphasizes the "2-minute scanning strategy" to avoid the "sunk cost fallacy" (committing too much time to a question that won't solve). Considering the specific question types highlighted (e.g., lengthy Arithmetic, multi-chart DILR sets, contextual VARC questions), detail how candidates should execute this 2-minute scan in each section to effectively differentiate between a "doable but lengthy" question (which should be skipped initially) and a "doable and quick" question (which should be attempted immediately).